
By Asif Razzaq
Publication Date: 2026-04-11 20:10:00
Long-chain reasoning is one of the most compute-intensive tasks in modern large language models. When a model like DeepSeek-R1 or Qwen3 works through a complex math problem, it can generate tens of thousands of tokens before arriving at an answer. Every one of those tokens must be stored in what is called the KV cache — a memory structure that holds the Key and Value vectors the model needs to attend back to during generation. The longer the reasoning chain, the larger the KV cache grows, and for many deployment scenarios, especially on consumer hardware, this growth eventually exhausts GPU memory entirely.
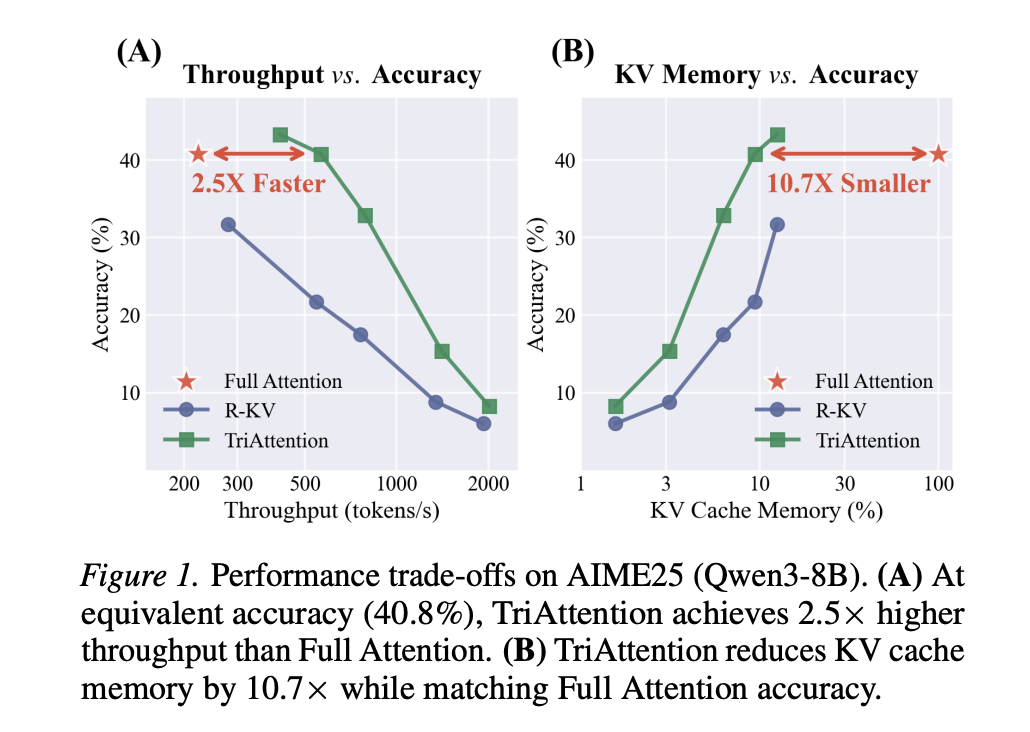
A team of researchers from MIT, NVIDIA, and Zhejiang University proposed a method called TriAttention that directly addresses this problem. On the AIME25 mathematical reasoning benchmark with 32K-token generation, TriAttention matches Full Attention accuracy while achieving 2.5× higher throughput or 10.7× KV memory reduction. Leading baselines achieve only about half the accuracy at the same efficiency level.
The Problem with Existing KV Cache Compression
To understand why TriAttention is important, it helps to understand the standard approach to KV cache compression. Most existing methods — including SnapKV, H2O, and R-KV — work by estimating which tokens in the KV cache are important and evicting the rest. Importance is typically estimated by looking at attention scores: if a key receives high…


