
: A Super Powerful and Open Large Audio-Language Model")
By Asif Razzaq
Publication Date: 2026-04-14 08:24:00
Understanding audio has always been the multimodal frontier that lags behind vision. While image-language models have rapidly scaled toward real-world deployment, building open models that robustly reason over speech, environmental sounds, and music — especially at length — has remained quite hard. NVIDIA and the University of Maryland researchers are now taking a direct swing at that gap.
The research team have released Audio Flamingo Next (AF-Next), the most capable model in the Audio Flamingo series and a fully open Large Audio-Language Model (LALM) trained on internet-scale audio data.
Audio Flamingo Next (AF-Next) comes in three specialized variants for different use cases. The release includes AF-Next-Instruct for general question answering, AF-Next-Think for advanced multi-step reasoning, and AF-Next-Captioner for detailed audio captioning.
What is a Large Audio-Language Model (LALM)?
A Large Audio-Language Model (LALM) pairs an audio encoder with a decoder-only language model to enable question answering, captioning, transcription, and reasoning directly over audio inputs. Think of it as the audio equivalent of a vision-language model like LLaVA or GPT-4V, but designed to handle speech, environmental sounds, and music simultaneously — within a single unified model.
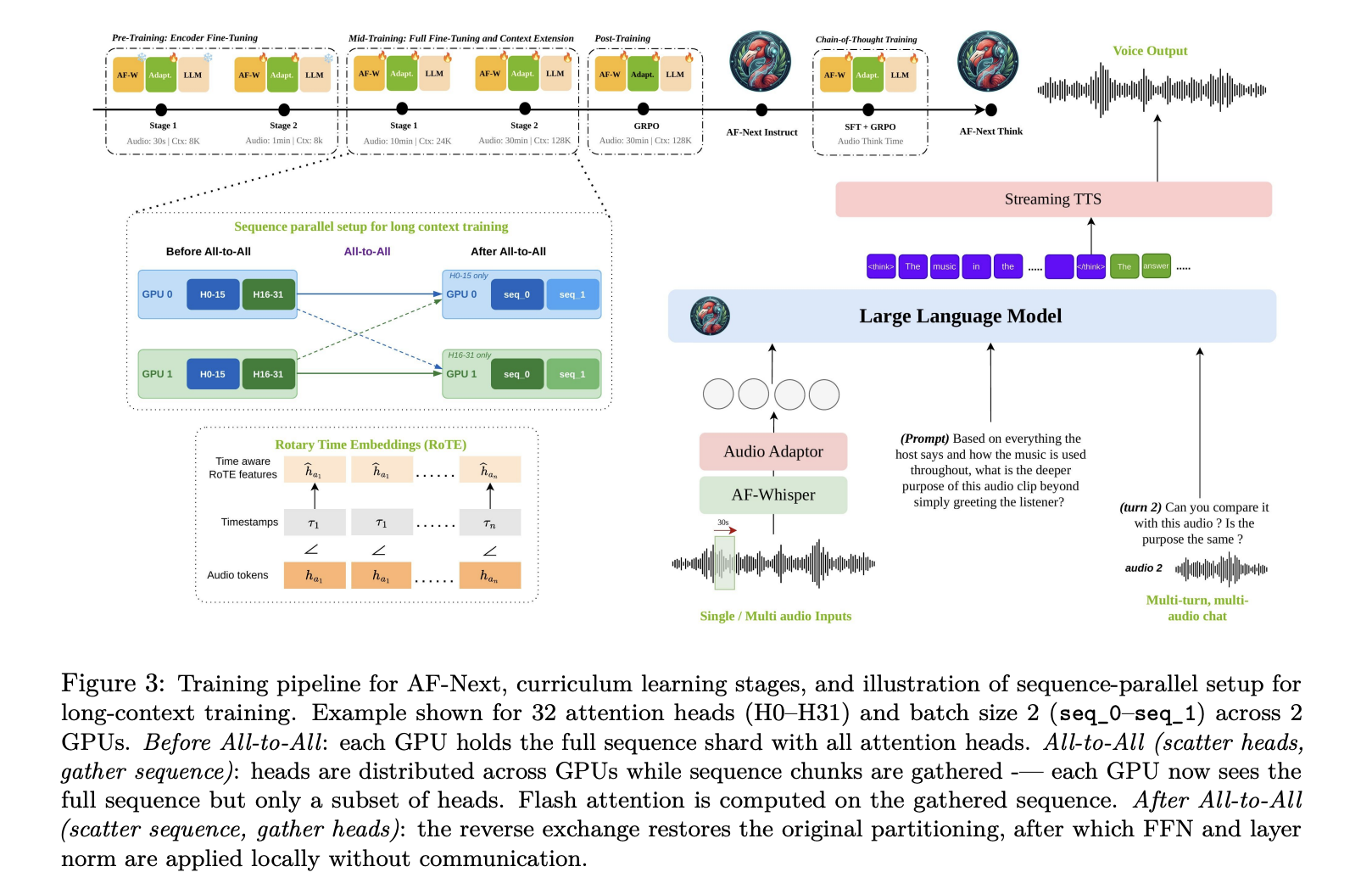
The Architecture: Four Components Working in a Pipeline
AF-Next is built around four main components: First is the AF-Whisper…


